Web API plugin
The Web API plugin allows you to query data from any HTTP API that returns JSON and visualize that data. This is particularly useful if there isn't a SquaredUp plugin available for your data source.
Plugins connect SquaredUp to your data sources. There are lots of plugins available with new ones being made available regularly, see SquaredUp: Plugins. Plugins can be used to add new data sources from Data sources on the left-hand menu. Most data sources need credentials like an API key, access token or other authentication methods.
On-premises plugins allow you to connect to APIs hosted on-prem.
If there isn't a plugin available for your data source, then you can use the Web API plugin to connect to any HTTP API that returns JSON. Alternatively, you can build and customize your own plugin. Contact us for more information.
This article covers:
How to add a data source using the Web API plugin
How to add a data source using the Web API On-Premise plugin
Creating a data stream using the configurable data stream
Writing a custom data stream (advanced users)
How to add a data source using the Web API plugin
Configure the data source in SquaredUp.
If you're not using a cloud-based API and instead are accessing an API on your internal network, you should use the on-premises Web API plugin, see How to add a data source using the Web API On-Premise plugin.
To add a data source click on the + next to Data Sources on the left-hand menu in SquaredUp. Search for the data source and click on it to open the Configure data source page.
Display Name:
Enter a name for your data source. This helps you to identify this data source in the list of your data sources.
Base URL:
Enter the base URL of the API to be used for requests, for example
https://swapi.dev/apiQuery arguments:
Add any parameters that should be added to the Base URL.
None needed for the Star Wars API.
Authentication:
None or Basic
For example, None for the Star Wars API.
Headers can be added if required.
No header information needed for the Star Wars API.
Ignore Certificate errors:
If you activate this checkbox the data source will ignore certificate errors when accessing the server. This is useful if you have self-signed certificates.
Test endpoint:
Optionally, you can tick Test endpoint to run a test request and see an example payload.
 Test endpoint
Test endpointEnter the details of an endpoint you'd like to run a test against to see what is returned. The information entered here is only used for the test.
Endpoint path to test:
Enter an endpoint path. For example, for the Star Wars API you can enter
peopleto use the People API method.Additional headers for the test:
Enter any additional header names and values to be used for the test.
None are needed for the Star Wars API.
HTTP method for the test:
GET or POST
For example, for Star Wars choose GET.
Query arguments for the test GET:
If you chose GET you can optionally add any query arguments to be used for the test.
Body for test POST:
If you chose POST you can optionally enter a JSON string representing the body of the POST request.
Click Send.
The Result box will show the resulting payload.
Optionally, select whether you would like to restrict access to this data source instance. By default, restricted access is set to off.
Restrict access to this data sourceThe term data source here really means data source instance. For example, a user may configure two instances of the AWS data source, one for their development environment and one for production. In that case, each data source instance has its own access control settings.
By default, Restrict access to this data source is set to off. The data source can be viewed, edited and administered by anyone. If you would like to control who has access to this data source, switch Restrict access to this data source to on.
Use the Restrict access to this data source dropdown to control who has access to the workspace:
By default, the user setting the permissions for the data source will be given Full Control and the Everyone group will be given Link to workspace permissions.
Tailor access to the data source, as required, by selecting individual users or user groups from the dropdown and giving them Link to workspace or Full Control permissions.
If the user is not available from the dropdown, you are able to invite them to the data source by typing in their email address and then clicking Add. The new user will then receive an email inviting them to create an account on SquaredUp. Once the account has been created, they will gain access to the organization.
At least one user or group must be given Full Control.
Admin users can edit the configuration, modify the Access Control List (ACL) and delete the data source, regardless of the ACL chosen.
Data source access levelsAccess Level:
Link to workspace
- User can link the data source to any workspace they have at least Editor permissions for.
- Data from the data source can then be viewed by anyone with any access to the workspace.
User can share the data source data with anyone they want.
User cannot configure the data source in any way, or delete it.
Full Control - User can change the data source configuration, ACL, and delete the data source.
See Access control for more information.
Click Add.
You can also add a data source from Settings > Data Sources > Add data source, but sample dashboards are not added when using this method.
How to add a data source using the Web API On-Premise plugin
The Web API on-premise plugin allows you to add a data source that connects to an API on your internal network.
Note: This data source is an on-premises data source.
An on-premises data source connects a service running in your internal network to SquaredUp. They require an agent installed on a machine that has access to your internal network.
Configure and deploy an agent
If you have already created an agent in SquaredUp that you can use for this data source, you can skip this step and choose the agent group you want to use while adding the data source.
Create a unique API key for your agent and add the agent to an agent group in SquaredUp.
You create an API key by creating an agent in SquaredUp:
Go to Settings > Relay and add an Agent.
Give the new agent a name and a description that helps you identify where the agent is installed. For example:
Name: server1.domain.localDescription: Test server in production domain
Choose the Agent Group for this agent:
If you already have agent groups, assign it to an existing group and click create.
If you don't have any agent groups yet or want to assign the new agent to a new group, leave the Agent Groups field empty and click create. Then create the agent group by clicking on Add Agent Group and select the new agent in the Agents field for the new group.
After you created the agent, the API key for this agent will be shown to you. Copy the key and store it until you inserted the key into the configuration of the agent you want to deploy on your machine.
The API key will only be displayed to you once. If you lose this API key, you need to generate a new one (by creating a new agent) and any references to the old API key in the configuration of the agent you deployed on your machine will need to be updated.
- The agent status will show as gray until the next stage of configuring the service is completed successfully.
Deploy the agent on a machine that has access to the service the data source connects to.
Download the latest release of the SquaredUp agent zip file, by clicking the download icon under Options next to the agent you have just added.
Prerequisites for agentsThe agent needs to run on a Windows machine that has access to the entry point for the on-premises data source
Make sure the agent is able to make outbound connections on port 443 (no inbound required) to SquaredUp, *.amazonaws.com and Microsoft APIs (Azure Relay).
Optional DNS-based restrictions: *.servicebus.windows.net
For information about Relay Agent versions see Release Notes - Relay Agent
On a Windows machine, with access to the entry point your data source needs to use, extract the downloaded zip file.
In the folder of the extracted zip file, open PowerShell as an administrator and run the following command:
Copy./Install-SQUPAgent.ps1 -ApiKey "key" -AsService -ServiceSuffix "name" -ServiceAccount domain\usernameParameters to replace:
-ApiKey "key"Mandatory Replace keywith the API key you created for the agent in SquaredUp-AsServiceRecommended Run the agent as a service on the machine -ServiceSuffix "name"Optional To change the default service name of squpagent replace namewith your new service name.-ServiceAccount domain\usernameOptional To run the agent as a domain service account (for example, for the SCOM data source), provide the username as domain\usernameand it will prompt for the password when it sets up the service-InstallPathOptional Specify a folder location for where the agent will be installed. If this is not specified then the agent will be installed in the folder where the zip file is extracted. Consider restricting access to the folder where the agent is installed to prevent anyone from updating or viewing the configuration files.
Configure a domain service account using the installation script, for example:
./Install-SQUPAgent.ps1 -ApiKey "key" -AsService -ServiceAccount domain\usernamewhere
keyis the API key, anddomain\usernameis the domain service accountAlternatively, in Services > SquaredUp Cloud Agent > Properties select the account on the Log On tab.
Use a dedicated user account for the agent's service identity. Create a special service account for this domain service account, do not use an existing user account.
The account (typically a service account) needs to have the log on as a service permission.
Adjust any permissions for the service and start the service.
How to start the agent serviceYou can start the agent service from Services > SquaredUp Cloud Agent, or using PowerShell using either:
Start-Service -Name <ServiceName>Where
<ServiceName>should be replaced with the service name shown in brackets in the upgrade script output (or Properties of the service).For example:
Start-Service -Name squpagentor
Start-Service -DisplayName <DisplayName>Where
<DisplayName>should be replaced with the service name shown before the brackets in the upgrade script output (or Properties of the service).How to find the agent folder location or Service name in PropertiesLook at the Properties of the SquaredUp Cloud Agent service:
On the server running the agent, open Services
Scroll down to the SquaredUp Cloud Agent in the list
Right-click on the SquaredUp Cloud Agent service and then Properties
Here you can see the Service name, Display name and Path to the agent folder.
You can also start or stop the service from here.
- Check the agent status in SquaredUp Settings > Relay
Running the agent as a domain service accountBy default, the SquaredUp agent service uses the local system identity, but this can be changed to a domain service account if required, for example for the SCOM data source.
Add a Web API On-Premise data source in SquaredUp
Configure the data source in SquaredUp:
To add a data source click on the + next to Data Sources on the left-hand menu in SquaredUp. Search for the data source and click on it to open the Configure data source page.
Display Name:
Enter a name for your data source. This helps you to identify this data source in the list of your data sources.
You may find it useful to put the API URL in the display name. For example
Star Wars https://swapi.dev/apiAgent Group:
Select the Agent Group that contains the agent(s) you want to use.
Base URL:
Enter the base URL of the API to be used for requests, for example
https://swapi.dev/apiQuery arguments:
Add any parameters that should be added to the Base URL.
None needed for the Star Wars API.
Authentication:
None or Basic
For example, None for the Star Wars API.
Headers can be added if required.
No header information needed for the Star Wars API.
Ignore Certificate errors:
If you activate this checkbox the data source will ignore certificate errors when accessing the server. This is useful if you have self-signed certificates.
Test endpoint:
Optionally, you can tick Test endpoint to run a test request and see an example payload.
Test endpointEnter the details of an endpoint you'd like to run a test against to see what is returned. The information entered here is only used for the test.
Endpoint path to test:
Enter an endpoint path. For example, for the Star Wars API you can enter
peopleto use the People API method.Additional headers for the test:
Enter any additional header names and values to be used for the test.
None are needed for the Star Wars API.
HTTP method for the test:
GET or POST
For example, for Star Wars choose GET.
Query arguments for the test GET:
If you chose GET you can optionally add any query arguments to be used for the test.
Body for test POST:
If you chose POST you can optionally enter a JSON string representing the body of the POST request.
Click Send.
The Result box will show the resulting payload.
Optionally, select whether you would like to restrict access to this data source instance. By default, restricted access is set to off.
Restrict access to this data sourceThe term data source here really means data source instance. For example, a user may configure two instances of the AWS data source, one for their development environment and one for production. In that case, each data source instance has its own access control settings.
By default, Restrict access to this data source is set to off. The data source can be viewed, edited and administered by anyone. If you would like to control who has access to this data source, switch Restrict access to this data source to on.
Use the Restrict access to this data source dropdown to control who has access to the workspace:
By default, the user setting the permissions for the data source will be given Full Control and the Everyone group will be given Link to workspace permissions.
Tailor access to the data source, as required, by selecting individual users or user groups from the dropdown and giving them Link to workspace or Full Control permissions.
If the user is not available from the dropdown, you are able to invite them to the data source by typing in their email address and then clicking Add. The new user will then receive an email inviting them to create an account on SquaredUp. Once the account has been created, they will gain access to the organization.
At least one user or group must be given Full Control.
Admin users can edit the configuration, modify the Access Control List (ACL) and delete the data source, regardless of the ACL chosen.
Data source access levelsAccess Level:
Link to workspace
- User can link the data source to any workspace they have at least Editor permissions for.
- Data from the data source can then be viewed by anyone with any access to the workspace.
User can share the data source data with anyone they want.
User cannot configure the data source in any way, or delete it.
Full Control - User can change the data source configuration, ACL, and delete the data source.
See Access control for more information.
Click Add.
You can also add a data source from Settings > Data Sources > Add data source, but sample dashboards are not added when using this method.
Using the Web API data streams
Data streams standardize data from all the different shapes and formats your tools use into a straightforward tabular format. While creating a tile you can tweak data streams by grouping or aggregating specific columns. Depending on the kind of data, SquaredUp will automatically suggest how to visualize the result, for example as a table or line graph.
Data streams can be either global or scoped:
Global data streams are unscoped and return information of a general nature (e.g. "Get the current number of unused hosts").
A scoped data stream gets information relevant to the specific set objects supplied in the tile scope (e.g. "Get the current session count for these hosts").
How to create a data stream for a data source:
Create a data stream using the configurable data stream form (simplest option) see Creating a data stream using the configurable data stream
Write a custom data stream (advanced use) see Writing a custom data stream (advanced users)
Creating a data stream using the configurable data stream
A configurable data stream allows you to easily create new data streams specific to your needs, by entering information into a form, such as metric names or queries. Configurable data streams have a cog icon next to their name in the tile editor.
Any data stream you create can be edited by clicking the edit button (pencil) next to it in the tile editor, and also from Settings > Advanced > Data Streams.
The Web API plugin adds one configurable data stream (HTTP Request) which allows you to create a global data stream to query data from any HTTP API that returns JSON.
The steps for creating the data stream are very similar to those for the Run test endpoint test (when adding a Web API data source), with a couple of additional fields:
Add a new data tile and scope to an instance of a Web API data source. For example
Star Wars https://swapi.dev/apicreated earlier.Choose the + <Web API instance name> - HTTP Request data stream.
Display Name:
Enter a name for this data stream. For example,
Star Wars PeopleThe Base URL from the Web API instance is shown.
Endpoint path:
Enter an endpoint path. For example, for the Star Wars API you can type
peopleto use the People API method.Supports timeframe mustache parametersA mustache parameter is a dynamic value, the actual value will be inserted to replace the field in curly braces. For example,
{{timeframe.start}}will insert the start time based on the timeframe configured within the tile, or{{name}}will insert the name of the object(s) in scope.This data stream supports timeframe parameters:
Parameter
Replacement value
Type
{{timeframe.start}}
2022-03-13T19:45:00.000Z
string
{{timeframe.unixStart}}
1647200700
number
{{timeframe.end}}
2022-03-14T19:45:00.000Z
string
{{timeframe.unixEnd}}
1647287100
number
{{timeframe.enum}}
last24hours
string
{{timeframe.interval}}
PT15M
string
{{timeframe.durationSeconds}}
86400
number
{{timeframe.durationMinutes}}
1440
number
{{timeframe.durationHours}}
24
number
Additional headers for this request:
Enter any additional header names and values to be used.
None are needed for the Star Wars API.
Supports timeframe mustache parameters (in values field)A mustache parameter is a dynamic value, the actual value will be inserted to replace the field in curly braces. For example,
{{timeframe.start}}will insert the start time based on the timeframe configured within the tile, or{{name}}will insert the name of the object(s) in scope.This data stream supports timeframe parameters:
Parameter
Replacement value
Type
{{timeframe.start}}
2022-03-13T19:45:00.000Z
string
{{timeframe.unixStart}}
1647200700
number
{{timeframe.end}}
2022-03-14T19:45:00.000Z
string
{{timeframe.unixEnd}}
1647287100
number
{{timeframe.enum}}
last24hours
string
{{timeframe.interval}}
PT15M
string
{{timeframe.durationSeconds}}
86400
number
{{timeframe.durationMinutes}}
1440
number
{{timeframe.durationHours}}
24
number
HTTP method:
GET or POST
For example, for Star Wars choose GET.
Query arguments for GET:
If you chose GET you can optionally add any query arguments to be used.
Supports timeframe mustache parameters (in values field)A mustache parameter is a dynamic value, the actual value will be inserted to replace the field in curly braces. For example,
{{timeframe.start}}will insert the start time based on the timeframe configured within the tile, or{{name}}will insert the name of the object(s) in scope.This data stream supports timeframe parameters:
Parameter
Replacement value
Type
{{timeframe.start}}
2022-03-13T19:45:00.000Z
string
{{timeframe.unixStart}}
1647200700
number
{{timeframe.end}}
2022-03-14T19:45:00.000Z
string
{{timeframe.unixEnd}}
1647287100
number
{{timeframe.enum}}
last24hours
string
{{timeframe.interval}}
PT15M
string
{{timeframe.durationSeconds}}
86400
number
{{timeframe.durationMinutes}}
1440
number
{{timeframe.durationHours}}
24
number
Body for POST:
If you chose POST you can optionally enter a JSON string representing the body of the POST request.
Supports timeframe mustache parametersA mustache parameter is a dynamic value, the actual value will be inserted to replace the field in curly braces. For example,
{{timeframe.start}}will insert the start time based on the timeframe configured within the tile, or{{name}}will insert the name of the object(s) in scope.This data stream supports timeframe parameters:
Parameter
Replacement value
Type
{{timeframe.start}}
2022-03-13T19:45:00.000Z
string
{{timeframe.unixStart}}
1647200700
number
{{timeframe.end}}
2022-03-14T19:45:00.000Z
string
{{timeframe.unixEnd}}
1647287100
number
{{timeframe.enum}}
last24hours
string
{{timeframe.interval}}
PT15M
string
{{timeframe.durationSeconds}}
86400
number
{{timeframe.durationMinutes}}
1440
number
{{timeframe.durationHours}}
24
number
Click Send. The Result box will show an example of the resulting payload.
Path to data:
This is where you enter the location of the results set that is returned. The Result box shows you a preview of the data returned, so you can check the location of the data returned, and use that in the Path to data.
For example, for the Star Wars API enter
results.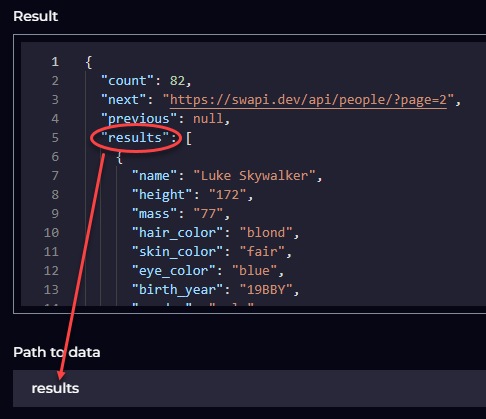
Expand inner objects:
Objects inside the requested data path will be used to make extra columns of data.
What exactly does Expand inner objects do?Let's keep this example payload in mind:
Copyconst payload = {
a1: 'a1',
a2: 111,
a3: true,
arr: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12],
obj: {
b1: 'b1',
b2: 222,
b3: true,
sub1Arr: [
{ x1: 'x1', x2: 6661, x3: { y1: 'y11', y2: 'y21' } },
{ x1: 'x2', x2: 6662, x3: { y1: 'y12', y2: 'y22' } }
],
subObj: {
c1: 'c1',
c2: 333,
c3: false
}
}
};If Expand inner objects is unchecked (off)
If Path to data points to an array, so values like
arr,obj.sub1Arr, the data stream is going to return one row for each element (with no limit of 10 involved here).arrwill return rows with a single column calledvaluewith all the integers from 1 to 12 (incl.)Copy
value
1
2
...
11
12obj.sub1Arrwill return two rows and three columns, like:Copy
x1 x2 x3
"x1" 6661 "[object Object]"
"x2" 6662 "[object Object]"If Path to data points to a scalar, the data stream will return a single row with a single column called
resultand the value will be the scalar, for example,obj.b2will return:Copy
result
222If Path to data points to an object, the data stream will return a single row with columns for each of the properties, for example,
objwill return:Copy
b1 b2 b3 sub1Arr subObj
"b1" 222 true "[object Array]" "[object Object]"If Expand inner objects is checked (on)
Behavior differs wherever one of the
[object XXX]placeholders appeared before.For example,
obj.sub1Arrwill return two rows and four columns, like:Copy
x1 x2 x3.y1 x3.y2
"x1" 6661 "y11" "y21"
"x2" 6662 "y12" "y22"Also, nested arrays will be expanded (but only to a maximum of ten elements.
Click Save.
Writing a custom data stream (advanced users)
A custom data stream is a data stream that you, as an advanced user, can write yourself. In Settings > Data Streams you can also edit any data stream created from a configurable data stream, to customize it.
You may wish to create your own custom data stream for an HTTP Request using the information below. When writing your own data stream you can choose either a global or scoped entry point. You will need to write your own custom data stream if you want a scoped data stream, because the configurable data stream HTTP Request can only create a global data stream.
Go to Settings > Data Streams.
Click Add new Data Stream.
Enter a display name for your Data Stream.
Note: The display name is the name that you use to identify your Data Stream in SquaredUp. It has no technical impact and doesn't need to be referenced in the Data Stream's code.
Choose the Data Source this Data Stream is for.
After you've chosen the data source a new field Entry Point appears.
Entry point and code:
What is an entry point?Each data stream uses an entry point, which can either be global (unscoped) or scoped, and this determines whether the data stream uses the tile scope.
Data streams can be either global or scoped:
Global data streams are unscoped and return information of a general nature (e.g. "Get the current number of unused hosts").
A scoped data stream gets information relevant to the specific set objects supplied in the tile scope (e.g. "Get the current session count for these hosts").
To find out which entry point to select and get code examples for the Code field, see the help below.
Click Save to save your Data Stream.
Example of a scoped HTTP Request data stream
Creating a custom data stream allows you to created a scoped data stream, i.e. a data stream that makes use of objects in the scope.
Which entry point do I have to select from the dropdown?
HTTP Request (scoped)
Each data stream uses an entry point, which can either be global (unscoped) or scoped, and this determines whether the data stream uses the tile scope.
Data streams can be either global or scoped:
Global data streams are unscoped and return information of a general nature (e.g. "Get the current number of unused hosts").
A scoped data stream gets information relevant to the specific set objects supplied in the tile scope (e.g. "Get the current session count for these hosts").
Code example:
{
"name": "scope example",
"matches": "all",
"dataSourceConfig": {
"endpointPath": "post",
"httpMethod": "post",
"idSeparator": "], [",
"headers": [
{
"key": "header1",
"value": "header1Val"
},
{
"key": "sourceIds",
"value": "[{{sourceIds}}]"
}
],
"expandInnerObjects": true
},
"rowPath": []
}You should set the matches statement so that your custom data stream appears when you select the appropriate object types in the tile editor. You can use additional mustache constructs when using the scoped entry point: targetNodes, sourceId, sourceIds in selected dataSourceConfig parameters as shown below. The separator inserted between sourceId values in the sourceIds replacement string can be changed by setting idSeparator in dataSourceConfig.
Parameters
name parameterMandatory
The internal name of the data stream. Can be used the refer to this data stream in a tile's JSON instead of using the data stream's internal ID.
dataSourceConfig parametersendpointPath | Mandatory | (string) - the endpoint path relative to the data source config's base URL to be queried (supports mustache parameters) |
httpMethod | Mandatory | (string) - "get" or "post" |
headers | Optional | (array of key, value pairs) - any additional headers for this request (supports mustache parameters in |
getArgs | Optional | (array of key, value pairs) - any additional query args (supports mustache parameters in |
postBody | Optional | (string) – only if httpMethod is "post", a JSON string defining the body (supports mustache parameters) |
idSeparator | Optional | (string) - this controls how the replacement value "sourceIds" is generated |
pathToData | Optional | (string) - where in the returned payload, the desired data is to be found |
expandInnerObjects | Optional | (boolean) - whether to expand inner objects and arrays in the desired data |
matches parametersNote: Defining the matches parameter is mandatory.
With the matches parameter you define for which objects the data stream will be shown in SquaredUp. It works like this:
When you configure a tile, you have to choose its scope. If this scope contains objects you specified here in the matches parameter, the data stream will be shown in SquaredUp under Data Streams. If the scope doesn't contain objects specified here, the data stream will be hidden.
This keeps things clean and simple since you'll only see the data stream when it's relevant for the scope you chose. As a best practice you should limit the data stream to objects that make sense for the specific use case of this data stream.
Format for matches:
//If you want to specify only one value of an object property//
"matches": {
"ObjectProperty": {
"type": "equals",
"value": "ValueOfTheObjectProperty"
}
},
//If you want to specify multiple values for an object property//
"matches": {
"ObjectProperty": {
"type": "oneOf",
"values": ["ValueOfTheObjectProperty1", "ValueOfTheObjectProperty2", "ValueOfTheObjectProperty3"]
}
},Example for limiting a data stream to objects:
If you are using multiple values for the object property, you can decide if you want the data stream to be visible for objects that match all of the criteria or at least one of the criteria.
Lets say you have two values you want objects to have in order for the data stream to be visible for them:
a
SourceNameproperty with the valueAppDynamics(meaning objects that come from the AppDynamics data source)a
typeproperty with the valueapp(meaning application objects)
If you want the data stream to be visible only for objects that match both of the criteria, your code would look like this:
"matches": {
"sourceName": {
"type": "equals",
"value": "AppDynamics"
},
"type": {
"type": "equals",
"value": "app"
}
},If you want the data stream to be visible for objects that match at least one of the criteria, your code would look like this:
"matches": [
{
"sourceName": {
"type": "equals",
"value": "AppDynamics"
}
},
{
"type": {
"type": "equals",
"value": "app"
}
}
]Note: If you run into errors when configuring the matches parameter, check if you're dealing with a global entry point.
Data streams can be either global or scoped:
Global data streams are unscoped and return information of a general nature (e.g. "Get the current number of unused hosts").
A scoped data stream gets information relevant to the specific set objects supplied in the tile scope (e.g. "Get the current session count for these hosts").
Global entry points can't use specific objects in the matches parameter. You can identify global entry points by their name, they have "Global", "No Scope" or "Unscoped" added to their name.
There are two possible options for the matches parameter for global entry points:
"matches": "none", | When creating a tile, the Data Stream will be shown as long as no scope is selected. As soon as a scope is selected, the Data Stream will be hidden. |
"matches": "all", | When creating a tile, the Data Stream will be shown as soon as any scope is selected. |
rowPath parameterOptional
SquaredUp expects data in table form, and here's where you define how the table with your return data will be structured.
The rowpath (Path to data) will tell SquaredUp which items you want to convert into rows.
Example:
Let's say your return data looks like this:
{
"generalInfo": "some info",
"results": [
{
"name": "object 1",
"tags": [
"tag 1",
"tag 2",
"tag 3"
]
},
{
"name": "object 2",
"tags": [
"tag 1",
"tag 4"
]
}
]
}Now it depends on what data you want to base your table on, do you want rows per object or per tag?
If you want to see which objects have which tags, your rowpath would be results, and your table would look like this:
name | tags |
| object 1 | tag 1, tag 2, tag 3 |
| object 2 | tag 1, tag 4 |
If you want to turn each tag into a row and see to which objects they are applied, your rowpath would be results.tags, and your table would look like this:
tags | name |
| tag 1 | object 1 |
| tag 1 | object 2 |
| tag 2 | object 1 |
| tag 3 | object 1 |
| tag 4 | object 2 |
As you can see in the example, each parameter gets turned into a column and the items of the parameter you chose as the rowpath will be turned into rows.
metadata parameterOptional, but recommended
The metadata parameters are used to describe columns in order to tell SquaredUp what to do with them. You can do multiple things with the metadata parameters:
Specify how SquaredUp should interpret the columns you return and - to an extent - how their content displayed. You do this by giving each column a shape.
The shape you assign to a column tells SquaredUp what the column contains (for example, a number, a date, a currency, a URL, etc.). Based on the shape SquaredUp decides how to display this column, for example to display a URL as a clickable link.
Filter out or just hide columns.
Only the columns you define in
metadatawill be returned in the results. This helps you to filter out columns you don't need. If you need the content of a column but don't want to display it, you can use thevisibleparameter.Give columns a nicely readable display name.
Assign a specific role to columns
The role you assign to a column tells SquaredUp the purpose of the column. For example, if you have two different columns that contain numbers, you need to assign the role
valueto the column that contains the actual value you want to use in your visualization.
Note: If you don't specify any metadata, all columns will be returned and SquaredUp will do its best to determine which columns should be used for which purpose. If you're returning pretty simple data, for example just a string and a number, this can work fine. But if you're returning two columns with numbers it gets trickier for SquaredUp to figure out which one is the value and which one is just an ID or some other number.
Parameters:
Tip: Before you start specifying metadata, leave them empty at first and get all the raw data with your new data stream once. In order to do this, finish creating your custom data stream without metadata and create a tile with this data stream. The Table visualization will show you all raw data.
This will give you an overview about all columns and their content and help you decide which columns you need and what their shapes and roles should be. It's also essential for getting the correct column name to reference in the name parameter.
Use this information to go back to the data stream configuration and specifying the metadata.
name | Mandatory | Enter the name of the column you are referencing here. To find the name of a column, get the data from this data stream once without any metadata. See the tip above for how to do that. You'll see the column name when you hover over the column in the Table. |
displayName | Optional | Here you can give the column a user-friendly name |
shape | Recommended | The shape you assign to a column tells SquaredUp what the column contains (for example, a number, a date, a currency, a URL, etc.). Based on the shape SquaredUp decides how to display this column, for example to display a URL as a clickable link. Note: Please refer to the list of shapes below this table to see available shapes. |
role | Recommended | The role you assign to a column tells SquaredUp the purpose of the column. For example, if you have two different columns that contain numbers, you need to assign the role Note: Please refer to the list of roles below this table to see available roles. |
visible | Optional |
Use this if you need a columns content but don't need to display the column itself. Example: Column A contains the full link to a ticket in your ticket system. Column B contains the ticket ID. You want to use the ticket ID as a label for the link, turning the long URL into a much nicer to read "Ticket 123". This is why you need the content of column B, to assign it as a label for column A. But since the URL is now displayed as the ticket ID, it would be redundant to still display column B. This is why you hide column B with |
There are many different shapes you can use for your columns and the list of possible shapes gets expanded constantly:
Basic types, like:
boolean,date,number,stringCurrency types that get displayed with two decimal values and their currency symbol (for example $23,45), like:
currency(generic currency),eur,gbp,usdData types, like:
bytes,kilobytes,megabytesTime types, like:
seconds,milliseconds,timespanThe status type :
stateUtility types, like:
customUniturl(will be displayed as a link)
Tip:
Some shapes can be configured.
If a shape is configurable, you can edit how the shape displays data in SquaredUp.
label | A column containing user-friendly names. Line Graphs use this role to group data into series. so each label will get its own line in the Line Graph. |
link | A column containing a link that can be used as a drilldown in Status Blocks. |
timestamp | A column containing a date to use on the X -axis of a Line Graph. |
unitLabel | A column containing user-friendly labels for data series, e.g. ‘Duration’. Line Graphs can use this role to label the Y-axis. |
value | A column containing the numeric value you want to use in your visualization. |